
Dans le monde d’aujourd’hui axé sur la technologie, les données sont considérées comme la ressource la plus critique d’une organisation. Le traitement et la gestion des données, qui croissent à un rythme exponentiel sont les défis pressants auxquels sont confrontées presque toutes les organisations, pour la gestion des leurs opérations et la prise de décision…, Cette gigantesque croissance des données, communément appelée « Big Data » .
Dans cet article, nous allons découvrir la tendance « Big Data » d’un point vue fondamental, en définirons des concepts et principes communs. Nous jetterons également un regard sur certains processus et technologies actuellement utilisés, et à la fin de cette article, une étude de cas pour initier votre première architecture d’un projet BigData 🤩.
Concepts et terminologie :
L’expression Big data est un terme général qui désigne les stratégies et technologies non traditionnelles nécessaires pour recueillir, organiser, traiter et rassembler des informations à partir de grands ensembles de données en raison de leur caractéristique 3V : Volume, Vélocité et Variété.
- Volume :
– Large volume de données à l’ordre de Terabytes , ce qui exige une réflexion à chaque étape du cycle de vie de la transformation et du stockage.
– Parce que les exigences du traitement dépassent les capacités d’une seule machine (notions Cluster).
- Vélocité :
– Les données circulent fréquemment à grande vitesse dans le système à partir de sources multiples et sont souvent censées être traitées en temps réel, ce qui nécessite des systèmes robustes avec des composants hautement disponibles.
- Variété :
– Les données peuvent être consommées à partir de sources différentes et de format varié, comme les Logs serveur, de flux de médias sociaux et d’autres API externes, de capteurs de dispositifs physiques…
– Les systèmes d’information traditionnels peuvent s’attendre à ce que les données entrent dans le système d’une manière formatées et organisées, BigData acceptent et stockent généralement des données plus proches de leur état brut. Idéalement, toute transformation ou modification des données brutes se fera ultérieurement en mémoire dans une phase de traitement.
À quoi ressemble le cycle de vie Big Data ?
Les activités générales dans un système Big Data sont :
– L’introduction des données dans le système (Apache Storm , Apache Kafka … ) : Au cours de ce processus de lecture des données entrantes, un certain niveau d’analyse, de tri, filtrage et de formatage a généralement lieu. Ce processus est parfois appelé ETL, qui signifie « extract, transform, and load ». En gardant ces capacités à l’esprit, l’idéal serait que les données saisies soient aussi brutes que possible pour une plus grande flexibilité plus tard dans le processus.
– Stockage de téraoctets de données avec mises à jour fréquentes : Le volume énorme des données entrantes, les exigences de disponibilité et l’environnement distribué, demandent des systèmes de stockage plus complexes:
* Cela implique généralement l’utilisation d’un système de fichiers distribués pour le stockage de données brutes (Apache Hadoop’s HDFS);
* Les bases de données distribuées, en particulier les bases de données NoSQL, sont aussi bien adaptées à ce rôle car elles sont souvent conçues avec les mêmes considérations de disponibilité et de tolérance aux pannes, et peuvent traiter des données massives-hétérogènes (Apache Hbase, Apache Cassandra, MongoDB …).
🤙 Une comparaison de prise de décision entre ces différentes solutions de stockage viendra bientôt. « Don’t panic » 😉
– Analyse et traitement des données : Une fois les données disponibles, le système peut commencer à traiter les données pour faire apparaître les informations demandées. Cette couche d’analyse et de calcul peut-être la partie la plus diverse du système, car les exigences et la meilleure approche peuvent varier considérablement selon le type d’informations souhaitées. Les données sont souvent traitées de manière répétée, soit de manière itérative par un seul outil, soit en utilisant plusieurs outils, soit par Batch (traitement par lots) ou par Stream Temps Réel . => (Apache Hadoop’s MapReduce, ApacheSpark, ApacheFlink …). 🤙 Partie détaillée par la suite 🤗 .
– Visualisation des résultats : Le traitement en temps réel est fréquemment utilisé pour visualiser des mesures ou des indicateurs cruciales. Dans ces cas, des projets comme Prometheus peuvent être utiles pour traiter et visualiser les flux de données en temps réel.
- Une façon populaire de visualiser les données est la Solution Elastic Stack (Solution ELK). Composée d’outils pour la collecte des données, l’indexation et la recherche des données via ElasticSearch (ou Apache Solr), et la visualisation.
– Environnement Cluster : La mise en place d’une ensemble de machine de calcul (Cluster) est souvent la base de la technologie utilisée à chacune des étapes du cycle de vie :
- Ressources Machine : La combinaison de l’espace de stockage , CPU, et de la mémoire RAM est extrêmement importante pour Le traitement de grands ensembles de données .
- Haute disponibilité : Les clusters peuvent offrir différents niveaux de tolérance aux pannes et de garantie de disponibilité afin d’éviter que des pannes matérielles ou logicielles n’affectent l’accès aux données et leur traitement surtout en temps Réel .
- Évolutivité facile : Les Clusters facilitent l’évolution horizontale en ajoutant des machines supplémentaires au groupe pour augmanter la perofmance.
🤜 L’utilisation des clusters nécessite une solution pour orchestrer et coordonner le partage des ressources, planifier et gérer l’exécution des tâches sur les nœuds du Cluster (Gestionnaires tels que : YARN de Hadoop, Kubernets …)
Comparaison des Bases de données NoSql
NoSQL est un terme général qui fait référence aux bases de données conçues en dehors du modèle relationnel traditionnel. mais sont souvent bien adaptées aux systèmes BigData en raison de leur flexibilité et de leur architecture souvent distribuée, exemple des modèles de données NoSQL :
- Key-value Model : Ces Bases de données stockent et en gèrent des collections de paires clé-valeur sans aucune structure ni relation entre eux, une clé sert d’identifiant unique pour récupérer une valeur associée qui peut être aussi bien des objets simples, comme des entiers ou des chaînes de caractères, que des objets plus complexes, comme des structures JSON.
✍️ Les cas d’utilisation de ces BDs sont la mise en cache, la mise en file d’attente des messages et la gestion des sessions: => (Ex: Redis, MemcachedDB).
- Modèle orienté Colonne : sont des bases de données qui stockent les données en colonnes. Cela peut sembler similaire aux bases de données relationnelles traditionnelles, mais plutôt que de regrouper les colonnes dans des tableaux, chaque colonne est stockée dans un fichier système.
✍️ Ces BDs sont de plus en plus utilisés pour le stockages des flux temps réel, Data Anaytics, stockage de plusieurs valeurs pour une clé, car ce modèle permet d’assurer la haute disponibilité et le traitement rapide des requêtes. => (Ex: Apache Cassandra , Apache HBase)
- Modèle orienté Document : Ces bases de données stockent des données sous forme de documents identifiés par clé unique . Ces Documents stockent généralement les données comme JSON,XML,PDF …
- Modèle Graph (Noeuds et liens entres ce noeuds) : peut être considérés comme une sous-catégorie du modèle orienté Document, La différence est que les BDs Graph ajoutent une couche supplémentaire au modèle de document en mettant en évidence les relations entre les différents documents.
✍️ Ces bases de données sont couramment utilisées dans les cas où il est important de pouvoir tirer des relations entre les points de données ou dans les applications où les informations disponibles pour les utilisateurs finaux sont déterminées par leurs connexions à d’autres comme un réseau social, les moteurs de recherche et de recommandation… => (Ex : Neo4j, ArangoDB)
🧐 Dans le monde du BigData, on privilégie la haute disponibilité et la performance en temps de lecture/écriture, que de gradrer une structure de stockage normalisée.
Quels sont les Frameworks - Solutions BigData ?
Il existe de nombreuses frameworks et moteurs de traitement à choisir selon le besoin, on peut même faire la combinaison de plusieurs composants différents, cette interopérabilité entre les solutions est l’une des raisons pour lesquelles les systèmes BigData ont une grande flexibilité.
- Solution d’envoi et d’échange des données :
Apache Kafka est un système middleware orienté message « publish-subscribe-messaging » , distribué, scalable, tolérant aux pannes et sans single point of failure. Il peut être à la fois utilisé comme un système de messagerie publish/subscribe et comme une queue :
- Permet de découpler les applications clientes (Publisher) des applications de traitement (Consumer).
- Organiser et Découper le flux des messages en Topics de sorte à ce que les applications Consumer et Publisher travaillent à un régime optimal.
- Solutions de traitement par lots (Batch) : Une stratégie informatique qui implique le traitement de données en grands ensembles (ensembles finis de données). Ceci est généralement idéal pour les traitement non sensibles au temps. Le processus est démarré, et ultérieurement, les résultats sont renvoyés par le système.
Un projet qui a été le premier succès de l’open-source dans le domaine BigData. Il consiste en un système de fichiers distribués (en mode Cluster) appelé HDFS, avec un gestionnaire de cluster et de ressources appelé YARN. Ces capacités de traitement Batch sont fournies par le moteur de calcul MapReduce (Algorithme de calcul distribué), D’autres systèmes de calcul et d’analyse peuvent être utilisés en parallèle à MapReduce .
– Le Mode de fonctionnement Batch :
La technique de traitement de MapReduce utilisé par Hadoop suit l’algorithme « map, shuffle, reduce » en utilisant des paires clé-valeur. La procédure de base consiste à :
1) La lecture du jeu de données à partir du système de fichiers HDFS
2) Diviser l’ensemble de données en sous-dataSets et les répartir entre les nœuds (machines) disponibles dans le cluster.
3) Appliquer le calcul sur chaque nœud au sous-ensemble de données (les résultats intermédiaires sont retranscrits en HDFS)
4) Redistribution des résultats intermédiaires pour les regrouper par clé.
5) « Réduire » la valeur de chaque clé en combinant les résultats calculés par les différents nœuds
6) Inscrivez les résultats finaux calculés dans le HDFS
– Avantages et limites :
* Hadoop/MapReduce a un potentiel d’extensibilité incroyable, aussi que sa compatibilité et intégration avec d’autres frameworks (ou moteurs de calcul).
* Comme ce mode fait largement appel au stockage HDFS permanent, à la lecture et à l’écriture plusieurs fois par tâche, il a tendance à être assez lent.
* L’espace disque étant généralement l’une des ressources serveur les plus disponibles, cela signifie que MapReduce peut traiter d’énormes ensembles de données sur du matériel moins cher que certaines alternatives basé sur le stockage en mémoire RAM qui est plus couteuse (ex: Apache Spark)
✍️ Hadoop (avec son moteur de traitement MapReduce) est une solution bien testée qui est le mieux adapté au traitement de très grands ensembles de données où le temps n’est pas un facteur significatif.
- Solutions de traitement Temps Réel (Stream) : Cette stratégie consiste à calculer des flux des données infinies au fur et à mesure qu’elles entrent dans le système. Au lieu de définir des opérations à appliquer à un ensemble de données entier (Mode Batch), Ces solutions définissent des opérations qui seront appliquées à chaque élément de données entrant dans le système.
Est un framework de type CEP (Complex Event Processing) utilisé pour traiter des flux d’évènements (logs, alertes, Indicateurs …) qui nécessitent un traitement en temps quasi réel avec une latence extrêmement faible.
– Le Mode de fonctionnement : L’idée derrière Storm est de définir de petites opérations discrètes ou étapes, qui seront effectuées sur chaque donnée entrante, et de composer ce étapes ensuite en une topologie Graphe.
– Avantages et limites :
* Storm est probablement la meilleure solution actuellement disponible pour un traitement en temps quasi réel.
* Storm peut s’intégrer avec Hadoop .
* Comme Storm ne fait pas de traitement par Batch, vous devrez utiliser un logiciel supplémentaire si vous avez besoin de ces fonctionnalités (Trident peut vous le fournir).
* Storm supporte plusieurs Langages, et peut fournir un traitement à très faible latence, mais peut fournir des doublons et ne peut garantir l’ordre dans sa configuration par défaut.
Est un framewwork de traitement de flux qui est étroitement lié au système de message Apache Kafka et au gestionnaire de ressources YARN ce qui signifie qu’un cluster Hadoop est nécessaire (au moins HDFS et YARN).
– Avantages et limites :
* Bien que la référence aux HDFS (Hadoop FileSystem) entre chaque calcul entraîne de sérieux problèmes de performance lors du traitement par lots, Samza résout un certain nombre de problèmes lors du traitement des flux.
*Samza est capable de stocker l’état, en utilisant un système de contrôle tolérant aux pannes.
*Samza ne supporte pour l’instant que la JVM, ce qui signifie qu’il n’a pas la même flexibilité de langages comme Storm.
- Solutions de traitement Hybrides (Batch et Stream) : Certains frameworks de traitement peuvent traiter à la fois le mode Btch et le mode Stream TempsRéel. Ils simplifient les diverses exigences de traitement en permettant l’utilisation de composants et d’API pour les deux types de données.
Un moteur traitement par Batch de nouvelle génération avec des capacités de traitement mode Stream. Construit selon les mêmes principes que le moteur MapReduce de Hadoop, Spark se concentre principalement sur l’accélération du mode Batch en offrant un calcul et une optimisation du traitement en mémoire.
Spark peut être déployé comme un cluster autonome (s’il est couplé à une couche de stockage capable) ou peut se connecter à Hadoop comme alternative au moteur MapReduce.
– Le Mode de fonctionnement Batch : Contrairement à MapReduce, Spark traite toutes les données en mémoire, n’interagissant avec la couche de stockage que pour charger initialement les données en mémoire et à la fin pour pérsister les résultats finaux. Tous les résultats intermédiaires sont gérés en mémoire via des DataSets appelé RDD (Resilient Distributed Datasets) permettent une récupération complète après panne ou défaillance.
– Le Mode de fonctionnement Stream : SparkStreaming fourni un traitement de flux via le concept des micro-batches, qui fonctionne en mettant en mémoire tampon le flux par incréments de quelques secondes. Ceux-ci sont envoyés sous forme de petits ensembles de données fixes pour un traitement Batch. En pratique, cela fonctionne assez bien, mais cela conduit à une performance réduite que celle des véritables moteur de traitement temps réel.
– Avantages et limites :
* La raison évidente d’utiliser Spark au lieu de Hadoop MapReduce est la vitesse. Spark peut traiter les mêmes ensembles de données beaucoup plus rapidement grâce à sa stratégie de calcul en mémoire.
*Il peut être déployé comme un cluster autonome ou intégré à un cluster Hadoop existant.
* Il peut effectuer des traitements par lots et par flux, .Il bénéficie aussi d’un large soutien, de bibliothèques, connecteurs (DataBase Drivers …) et d’outils intégrés.
*Spark dispose également d’un écosystème de bibliothèques qui peuvent être utilisées pour MachineLearning, InteractiveQueries …
*Le Spark Streaming peut ne pas être approprié pour un traitement où une faible latence est impérative (Temps Réel).
*Comme la mémoire RAM et CPU sont généralement les plus couteuses que l’espace disque, Spark peut coûter plus cher à faire fonctionner.
Apache Flink est framewok de traitement de flux qui peut également gérer des tâches par Batch. Il considère que les Batchs sont simplement des flux de données ayant des limites finies (Au lieu de lire à partir d’un flux continu, il lit un ensemble de données délimité).
– Le Mode de fonctionnement Stream : Flink traite les données entrantes éléments par éléments comme un véritable flux. Le traitement des flux de Flink est capable de comprendre le concept de « temps d’événement », c’est-à-dire le moment où l’événement s’est réellement produit, et peut également gérer des sessions. Cela signifie qu’il peut garantir l’ordre et le regroupement de certaines manières intéressantes.
– Avantages et limites :
* Bien que Spark effectue un traitement par Batch et en flux, sa diffusion en continu n’est pas appropriée pour de nombreux cas d’utilisation en raison de son architecture micro-batch. L’approche « stream first » de Flink offre une faible latence, un débit élevé et un véritable traitement Temps Réel.
* Flink propose des optimisations pour le taitement Batch.
* Contrairement à Spark, Flink ne nécessite pas d’optimisation et d’ajustement manuels lorsque les caractéristiques des données qu’il traite changent. Il gère l’optimisation des tâches , le partitionnement des données et la mise en cache de manière automatique.
*Il s’intègre facilement à YARN, HDFS et Kafka. Flink peut exécuter des tâches écrites pour d’autres moteurs de traitement comme Hadoop et Storm avec des librairies de compatibilité.
*L’un des principaux inconvénients de Flink à l’heure actuelle est qu’il s’agit d’un projet encore très jeune (pas assez de support et de communauté).
Étude de cas : Plateforme de Dashboard Temps Réel
✍️ Nous allons présenter dans cette partie, un use case commun chez plusieurs organisations qui remontent et exploitent des flux infinies des données, c’est le Tableau de bord (Dashboard) des indicateurs émis par des sources différentes, soit pour un besoin d’opération ou une prise des décisions d’une façon réactive.
Nous verrons les problématiques associées et comment leur faire face, d’un point de vue Architectural, en se basant sur des technologies récentes qui ont déjà fait leurs preuves .
- Flux d’information élevé et varié :
L’infrastructure de ‘notre organisation reçoit en permanence plus que 1000 messages par secondes, varient entre les indicateurs de stock des points de ventes, signaux des dispositifs électroniques, positions géographiques du processus livraison et logistique, ainsi que des indicateurs analytiques du parcours et comportements des clients Web …
🧐 Alors, comment avons-nous résolu ce problème ? Nous avons choisi l’Apache Kafka pour cela. Kafka est un système de messagerie (Message Broker) distribué, évolutif et tolérant aux pannes, qui fournit par défaut un support de streaming.
- Choix de l’entrepôt de données : La quantité de données à stocker peut devenir considérable au fil du temps. Notre entrepôt de données doit supporter plusieurs téra-octets de données, Bien que les Bases de données relationnelles puisse stocker une grande quantité de données, il ne peut pas fournir des performances fiables en matière d’écriture et de lecture concurrente.
🧐 Nous avons eu une bonne expérience avec Cassandra dans le passé, c’est pourquoi c’était le premier choix. Apache Cassandra a les meilleures performances en écriture et en lecture. Comme Kafka, il est distribué, très évolutif ,tolérant aux pannes et Scalable horizontalement dans un environnement Cluster.
- Traitement des données énormes :
Le traitement des données doit être effectué à deux endroit. D’abord, pendant l’écriture, où nous devons transmettre les données de Kafka, les traiter et les sauvegarder pour Cassandra. Deuxièmement, pendant la génération des rapports d’activité, où nous devons lire le tableau complet de Cassandra, le joindre à d’autres sources de données et l’agréger sur plusieurs colonnes.
Pour ces deux exigences, Apache Spark était un choix parfait. En effet, Spark atteint des performances élevées pour faire les calculs sur les données, en utilisant le même code (Jobs, DataFrames RDD) nous pourrons donc y appliquer les mêmes opérations pour les deux modes Batch ou Stream . Enfin, Spark possède aussi une API SparkML, pour machine learning, ce qui offre plus des useCases possibles.
- Conception de l’Architecture : Plateforme Kafka-Spark-Cassandra
L’illustration suivante décrit une vue générale sur l’architecture choisie (Architecture Lambda) :
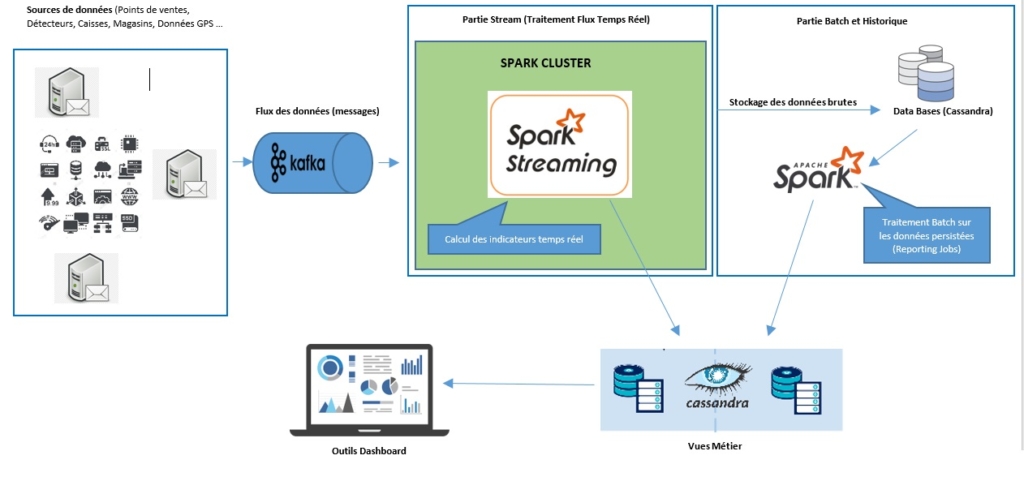
Nous allons expliquer le fonctionnement des interfaces présentés dans le schéma :
- Les applications clients émettrices (caisses, magasins …) publient les mises à jour des données (Ventes, Achats …), dans les topics du système kafka.
Spark Streaming va souscrire aux Topics Kafa (Topic stock,Topic achats,Topic alertes …) via le connecteur Kafka-Spark et récupérer sous forme de flux les messages, ce flux est découpé en RDDs (structures de données Spark) puis exécuter l’ensemble des opérations pour calculer les indicateurs du Dashboard stockés par la suite dans des vues métier (Vues Reporting).
- Parallèlement au traitement du flux de nos messages, nous les stockons dans notre BDD Cassandra (pour besoin ‘d’historisation) sous forme brute en utilisant le spark-cassandra-connector.
- Dans la partie Batch, les Jobs Spark sont programmés pour s’exécuter toutes les 24 heures et lire les données de la table Cassandra, exécuter une suite d’instructions (Agrégation,Jointures …) pour construire des données Reporting Historique, qui alimentent à nouveau des vues métiers.
✍️ Nous venons de donner des pistes et orientations pour développer une architecture du contexte BigData, qui repose sur des technologies open-source distribuées, tolérantes à la panne et scalables. Cet exemple montre le potentiel d’un trio (Kafka-Spark-Cassandra) de plus en plus utilisé qui connaît des retours d’expérience positifs, pour la réalisation d’architectures temps réel. Grâce à Spark, nous avons un ensemble d’outils de traitement de la donnée.
✍️ Il faut cependant comprendre en profondeur le fonctionnement et les limites de chacune de ces technologies pour modéliser correctement ses données, contourner les contraintes et profiter pleinement des ressources de son cluster.
Ce n’est pas la plus forte des espèces qui survit, ni la plus intelligente, mais celle qui réagit le mieux au changement.
Rédaction: yassine Abainou